Access Flow#
Once you have configured your Flow API you can access it over the network. There are multiple ways of doing this.
See Also
This page is about accessing the Flow with external clients.
You can also use the Jina Client, provided by us in the jina package.
It supports all the protocols listed here under a convenient, simple API.
Check its dedicated documentation page.
HTTP access#
Available Protocols
Jina Flows can use one of three protocols: gRPC, HTTP, or Websocket. Only Flows that use HTTP can be accessed via the methods described below.
Apart from using the Jina Client, the most common way of interacting with your deployed Flow is via HTTP.
You can always use post to interact with a Flow, using the /post HTTP endpoint.
Use HTTP client to send request#
With the help of OpenAPI schema, one can send data requests to a Flow via cURL, JavaScript, Postman, or any other HTTP client or programming library.
Here’s an example that uses cURL.
curl --request POST 'http://localhost:12345/post' --header 'Content-Type: application/json' -d '{"data": [{"text": "hello world"}],"execEndpoint": "/search"}'
Sample response
{
"requestId": "e2978837-e5cb-45c6-a36d-588cf9b24309",
"data": {
"docs": [
{
"id": "84d9538e-f5be-11eb-8383-c7034ef3edd4",
"granularity": 0,
"adjacency": 0,
"parentId": "",
"text": "hello world",
"chunks": [],
"weight": 0.0,
"matches": [],
"mimeType": "",
"tags": {
"mimeType": "",
"parentId": ""
},
"location": [],
"offset": 0,
"embedding": null,
"scores": {},
"modality": "",
"evaluations": {}
}
],
"groundtruths": []
},
"header": {
"execEndpoint": "/index",
"targetPeapod": "",
"noPropagate": false
},
"parameters": {},
"routes": [
{
"pod": "gateway",
"podId": "5742d5dd-43f1-451f-88e7-ece0588b7557",
"startTime": "2021-08-05T07:26:58.636258+00:00",
"endTime": "2021-08-05T07:26:58.636910+00:00",
"status": null
}
],
"status": {
"code": 0,
"description": "",
"exception": null
}
}
Sending a request from the front-end JavaScript code is a common use case too. Here’s how this would look like:
fetch('http://localhost:12345/post', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({"data": [{"text": "hello world"}],"execEndpoint": "/search"})
}).then(response => response.json()).then(data => console.log(data));
Output
{
"data": [
{
"id": "37e6f1bc7ec82fc4ba75691315ae54a6",
"text": "hello world"
"matches": ...
},
"header": {
"requestId": "c725217aa7714de88039866fb5aa93d2",
"execEndpoint": "/index",
"targetExecutor": ""
},
"routes": [
{
"executor": "gateway",
"startTime": "2022-04-01T13:11:57.992497+00:00",
"endTime": "2022-04-01T13:11:57.997802+00:00"
},
{
"executor": "executor0",
"startTime": "2022-04-01T13:11:57.993686+00:00",
"endTime": "2022-04-01T13:11:57.997274+00:00"
}
],
]
}
Arguments#
Your HTTP request can include the following parameters:
| Name | Required | Description | Example |
|---|---|---|---|
execEndpoint |
required | Executor endpoint to target | "execEndpoint": "/index" |
data |
optional | List specifying the input Documents | "data": [{"text": "hello"}, {"text": "world"}]. |
parameters |
optional | Dictionary of parameters to be sent to the Executors | "parameters": {"param1": "hello world"} |
targetExecutor |
optional | String indicating an Executor to target. Default targets all Executors | "targetExecutor": "MyExec" |
Instead of using the generic /post endpoint, you can directly use endpoints like /index or /search to perform a specific operation.
In this case your data request will be sent to the corresponding Executor endpoint, so the parameter execEndpoint does not need to be specified.
Example
curl --request POST \
'http://localhost:12345/search' \
--header 'Content-Type: application/json' -d '{"data": [{"text": "hello world"}]}'
fetch(
'http://localhost:12345/search',
{
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({"data": [{"text": "hello world"}]})
}).then(response => response.json()).then(data => console.log(data));
The response you receive includes data (an array of Documents), as well as the fields routes, parameters, and header.
See also: Flow REST API
For a more detailed descripton of the REST API of a generic Flow, including the complete request body schema and request samples, please check
For a specific deployed Flow, you can get the same overview by accessing the /redoc endpoint.
Use Swagger UI to send HTTP request#
Flows provide a customized Swagger UI which can be used to interact with the Flow visually, through a web browser.
Available Protocols
Only Flows that have enabled CORS expose the Swagger UI interface.
For a Flow that is exposed on port PORT, you can navigate to the Swagger UI via http://localhost:PORT/docs:
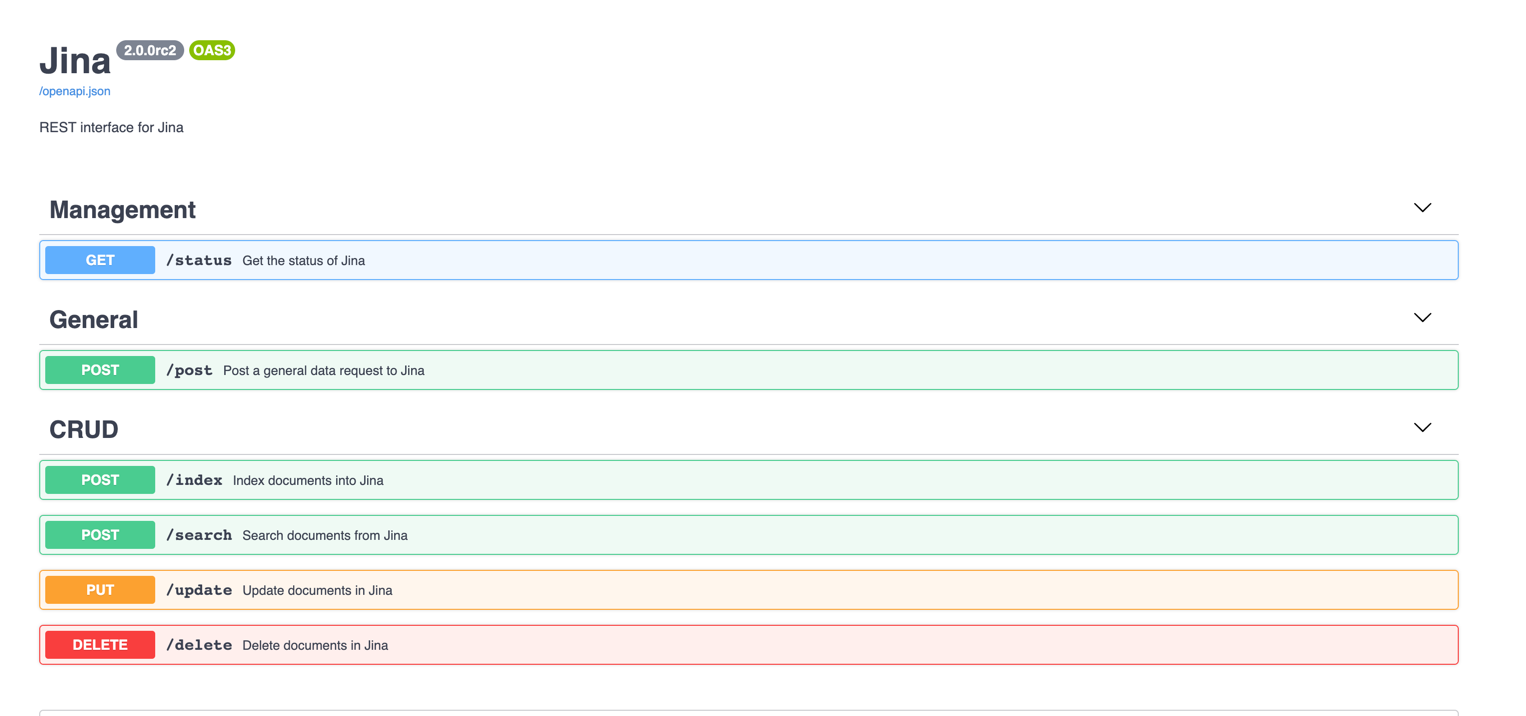
Here you can see all the endpoints that are exposed by the Flow, such as /search and /index.
To send a request, click on the endpoint you want to target, then on Try it out.
Now you can enter your HTTP request, and send it by clicking on Execute.
You can again use the REST HTTP request schema, but do not need to specify execEndpoint.
Below, in Responses, you can see the reply, together with a visual representation of the returned Documents.
Postman Collection#
Postman is an application that allows the testing of web APIs from a graphical interface. You can store all the templates for your REST APIs in it, using Collections.
We provide a suite of templates for the Jina Flow, in this collection. You can import it in Postman in Collections, with the Import button. It provides templates for the main operations. You need to create an Environment to define the {{url}} and {{port}} environment variables. These would be the hostname and the port where the Flow is listening.
This contribution was made by Jonathan Rowley, in our community Slack.
GraphQL Interface#
See Also
This article does not serve as the introduction to GraphQL. If you are not already familiar with GraphQL, we recommend you learn more about GraphQL from the official GraphQL documentation. You may also want to learn about Strawberry, the library that powers Jina’s GraphQL support.
Jina Flows that use the HTTP protocol can also provide a GraphQL API, which is located behind the /graphql endpoint.
GraphQL has the advantage of letting the user define their own response schema, which means that only the fields that are required
will be sent over the wire.
This is especially useful when the user does not need potentially large fields, like image tensors.
You can access the Flow from any GraphQL client, like for example, sgqlc.
from sgqlc.endpoint.http import HTTPEndpoint
HOSTNAME, PORT = ...
endpoint = HTTPEndpoint(url=f'{HOSTNAME}:{PORT}/graphql')
mut = '''
mutation {
docs(data: {text: "abcd"}) {
id
matches {
embedding
}
}
}
'''
response = endpoint(mut)
Mutations and arguments#
The Flow GraphQL API exposes the mutation docs, which sends its inputs to the Flow’s Executors,
just like HTTP post as described above.
A GraphQL mutation takes same set of arguments used in HTTP.
The response from GraphQL can include all fields available on a DocumentArray.
See Also
For more details on the GraphQL format of Document and DocumentArray, see the documentation page or the developer reference.
Fields#
The available fields in the GraphQL API are defined by the Document Strawberry type.
Essentially, you can ask for any property of a Document, including embedding, text, tensor, id, matches, tags,
and more.
gRPC#
If you want to create a gRPC client in another language, you will need to compile the Protobuf definitions. In Python, you can use our own client.
Websocket#
Websocket uses persistent connections between the client & Flow, hence allowing streaming use cases. While you can always use the Python client to stream requests like any other protocol, websocket allows streaming JSON from anywhere (CLI / Postman / any other programming language). The same set of arguments as HTTP can be used in the payload.
We use subprotocols to separate streaming JSON vs bytes.
The Flow defaults to json when a subprotocol is not passed during connection establishment (Our Python client uses bytes streaming by using jina.proto definition).
Hint
Choose Websocket over HTTP if you want to stream requests.
Choose Websocket over gRPC if
you want to stream using JSON, not bytes
your client language doesn’t support gRPC
you don’t want to compile the Protobuf definitions for your gRPC client
